Een nieuwe methode om neurale netwerken systematisch te laten denken kan ervoor zorgen dat kunstmatige intelligentie (AI) met minder data kan worden getraind. De afgelopen paar jaar hebben modellen als ChatGPT grote vooruitgang getoond. Maar er is heel veel data nodig om modellen te trainen, terwijl mensen met veel minder voorbeelden kunnen leren. Met de methode die Brenden Lake en Marco Baroni vorige week in het wetenschappelijke tijdschrift Nature publiceerden, kan kunstmatige intelligentie beter generaliseren en zo mogelijk sneller leren.
Mensen kunnen van nature generaliserend denken, dat zie je bijvoorbeeld aan hoe we wiskunde leren. Kinderen leren de getallen en het +-teken, en als een leraar uitlegt dat bijvoorbeeld 1+2=3, kunnen kinderen begrijpen dat dan ook geldt: 2+1=3. Dit wordt ook wel ‘compositioneel nadenken’ genoemd.
Compositionaliteit is een eigenschap van taal, en ook van wiskunde. Het houdt in dat de betekenis van een zin of rekensom afhankelijk is van de betekenis van de delen en de structuur. Compositioneel nadenken is niets anders dan gebruikmaken van deze compositionaliteit van taal. Zo kun je begrijpen wat nieuwe combinaties betekenen van woorden die je al kent.
Weinig training
Wie begrijpt hoe het +-teken werkt en de getallen kent, kan in principe alle getallen bij elkaar optellen. Neurale netwerken zijn van nature niet zo slim. Als een neuraal netwerk nog niet bekend is met het +-teken en wel geleerd heeft dat 1+2=3, kan het bijvoorbeeld alsnog dat het denkt dat 2+1=2, omdat het niet meteen kan begrijpen dat het +-teken altijd op een bepaalde manier werkt.
Met de nieuwe methode die de onderzoekers in Nature presenteren, kunnen programmeurs neurale netwerken compositionaliteit aanleren zodat ze met weinig training dit soort fouten kunnen voorkomen. Een van de onderzoekers, computationeel taalkundige Marco Baroni, vertelt over de telefoon waarom ze deze methode hebben ontwikkeld: „Het kost heel veel energie om grote modellen zoals ChatGPT te trainen en daarnaast willen we ook dat het ontwikkelen van AI niet alleen maar kan worden gedaan door grote bedrijven, zoals Google of Meta. Als er minder data nodig is voor het trainen, gaat dat makkelijker.”
Neurale netwerken zijn algoritmes die, op basis van bepaalde sets van inputs en outputs, zelf een manier kunnen ontwikkelen om met nieuwe inputs in te schatten welke output gegeven moet worden. De methode die Lake en Baroni hebben ontwikkeld, kan het soort neurale netwerken trainen die voor taalverwerking worden gebruikt, de familie waar ook ChatGPT toe behoort.
De onderzoekers gebruiken een techniek die meta-learning heet, waarbij AI op verschillende taken, in dit geval compositionaliteitstaken, achter elkaar wordt getraind. Het idee van meta-learning bestaat al sinds de jaren negentig, maar het is volgens Baroni pas sinds de laatste jaren dat neurale netwerken ver genoeg ontwikkeld zijn dat ze zo compositionaliteit kunnen aanleren.
onderzoekerMarco Baroni Het kost veel energie om grote modellen te trainen
Bij één zo’n compositionaliteitstaak krijgt het netwerk een aantal voorbeeldzinnen in een kunstmatige taal te zien met de correcte vertaling erbij. Bijvoorbeeld: ‘fax’ betekent een rode cirkel, ‘dup’ betekent een blauwe cirkel, en ‘fax kiki dup’ betekent een rode cirkel en dan een blauwe cirkel. Dan krijgt het neurale netwerk een nieuwe zin te zien in de kunstmatige taal, bijvoorbeeld ‘dup kiki fax’, en deze moet dan correct vertaald worden: eerst een blauwe cirkel en dan een rode cirkel.
Het netwerk wordt zo getraind dat het voor verschillende kunstmatige talen met verschillende grammatica’s een zo goed mogelijke vertaling geeft voor de nieuwe zin die het te zien krijgt. Eenmaal getraind kan het model net zo goed als mensen de compositionaliteitstaken uitvoeren. Ook laten de onderzoekers zien dat het getrainde netwerk beter een door henzelf ontwikkelde standaardtest voor systematisch generaliseren kan uitvoeren dan het ongetrainde netwerk.
Jelle Zuidema, universitair hoofddocent kunstmatige intelligentie aan de Universiteit van Amsterdam, legt uit dat het ongetrainde netwerk waar Lake en Baroni de generalisatietest mee uitvoeren wel heel klein is vergeleken met grote moderne modellen. „Hun model heeft ongeveer een miljoen parameters, terwijl bijvoorbeeld ChatGPT er miljarden heeft. Dat is dus wel duizend keer zo klein.” Misschien dat een groter model dus wel al meer zou kunnen dan het ongetrainde netwerk dat Lake en Baroni gebruiken.
Interessante vraag
ChatGPT kan zo veel dat het soms lijkt alsof het probleem van compositionaliteit al is opgelost. Zuidema: „Het is echt overweldigend hoe creatief ChatGPT met nieuwe combinaties van woorden kan omgaan. Maar we weten ook dat ChatGPT op heel veel data is getraind en het is onduidelijk hoe het model precies weet wat het moet antwoorden. Het kan zijn dat het gewoon zo veel heeft gezien dat veel eigenlijk helemaal niet zo nieuw is.”
Daarom is het volgens Zuidema wel een interessante vraag om te kijken hoe onderzoekers kleinere modellen met minder trainingsdata toch bepaalde compositionele taken kunnen laten oplossen: „Mensen walsen soms een beetje over deze vraag heen, maar die ChatGPT-modellen zijn zo duur om te draaien, er is echt een grote noodzaak om kleinere modellen slimmer te trainen.”
„Goedemorgen, uw legitimatie graag.” De vrouw achter de welkomstbalie van het UMC Utrecht kijkt strak naar haar computerscherm. Susan buigt voorover naar haar handtas op de rollator. Ze haalt er een paar brieven uit en stopt ze weer terug. De baliemedewerkster kijkt op. „Le-gi-ti-ma-tie.” Susan legt een brief met de ziekenhuisafspraak op de balie.
Dit soort plekken vreest Susan het meest, zegt ze na afloop. Intakebalies van instanties waar ze haar naam moet geven. „Ik denk altijd dat mensen direct doorhebben dat ik geen papieren heb en dat ze dan de politie bellen.”
De Tweede Kamer heeft begin deze maand een wet aangenomen die illegaliteit strafbaar moet maken. Het voorstel wordt na de zomer beoordeeld door de Eerste Kamer. Zowel de ongedocumenteerden zelf als de mensen die hen helpen, lopen het risico strafrechtelijk vervolgd te worden. Wie zijn de ongedocumenteerde mensen die door deze nieuwe wet ‘crimineel’ zouden worden? Hoe ziet hun leven eruit en wat verandert er?
NRC liep een dag lang mee met Susan (59) uit Ghana en Patrick (70) uit Algerije. Hun volledige namen zijn bekend bij de redactie. Beiden leven al tientallen jaren zonder papieren in Nederland. Waar voor Susan deze woensdag begint met een ziekenhuisafspraak in Utrecht, wacht Patrick ’s ochtends een bezoek aan zijn nieuwe advocaat.
Susan is al 24 jaar in Nederland en heeft geen verblijfsvergunning.
Patrick verblijft al meer dan veertig jaar ongedocumenteerd in Nederland.
Foto’s Mona van den Berg
11.00 uur
„Ik heb slecht geslapen”, zegt Patrick als hij op witte sneakers komt aanlopen. Hoewel dit zijn vierde advocaat is, oogt hij gespannen. Hij heeft een versleten Albert Heijn-tasje met papieren mee.
Het advocatenkantoor huist aan een Amsterdamse gracht, schuin boven een inloophuis voor daklozen. Patrick is in 1984 vanuit Algerije naar Nederland gekomen. In die veertig jaar heeft hij nooit een verblijfsvergunning kunnen bemachtigen. Nu hij zeventig is, wil hij een nieuwe poging doen.
Advocaat Annechien de Vries is not amused. Patrick is vergeten zijn dossier naar haar te mailen. „Nu heb ik me niet kunnen inlezen.”
Patrick: „Het is druk in m’n hoofd. Heel erg druk.”
De Vries: „Ik heb het ook heel erg druk. Dan moet u me het verhaal maar vertellen. Op welke gronden heeft u tot nu toe geprobeerd een verblijf te krijgen?”
Patrick overhandigt haar een plastic mapje.
De advocaat bladert een paar tellen door zijn papieren, maar het dossier is incompleet. Slechts een fractie van Patricks geschiedenis zit in het mapje. Beslissingen van de IND ontbreken, net als uitspraken van de rechtbank. De Vries: „Je moet info geven waar ik iets mee kan. Ik kan niet toveren. Hoe kan ik je anders helpen?”
Patrick stopt de papieren zwijgend terug in zijn plastic tas. „Bent u boos op mij?”
Patrick wil een zaak starten bij het Europees Hof, zegt hij, dat is hem aangeraden door zijn vorige advocaat. „Ik ben zeventig. Ik heb droge ogen. Suikerziekte. En polyneuropathie [een zenuwziekte die de spieren aantast]. Mijn lichaam doet overal pijn.”
De Vries: „Ben je hiervoor in behandeling?”
Patrick: „Ik krijg medicijnen.”
De Vries: „Via artikel 64 kun je aanspraak maken op uitstel van vertrek, om medische redenen. Maar dan moet je heel ziek zijn. Droge ogen is niks. Ik heb ook eczeem op mijn vingers. Als je kunt bewijzen dat je dood neervalt als je geen behandeling krijgt, maak je een kans.”
De Vries kijkt naar de klok. „Probeer een medisch dossier op te bouwen, en kom dan weer terug.” Ze wijst hem op maatschappelijk werkers in Amsterdam die hem daarbij kunnen helpen. „Ik kan je nu met nul, nada, niks helpen. Snap je dat?”
Patrick stopt zijn papieren zwijgend terug in zijn plastic tas. „Bent u boos op mij?”
De Vries: „Nee, ik ben niet boos op je. Ik heb heel veel cliënten, ik moet streng zijn. Succes, jongen.”
Patrick loopt stilletjes de trap af. Als hij weer op straat staat: „De koffie was goed he? Niet te sterk.”
Patrick heeft een kamer bij een HVO-Querido, een opvangorganisatie voor dak- en thuislozen.
Foto Mona van den Berg
13.00 uur
In het UMC Utrecht zijn de longen van Susan inmiddels nagekeken. Omdat ze bijna niet kan lopen, haalt een kennis haar op bij het ziekenhuis. De vervoerskosten worden betaald door het Wereldhuis van de protestantse kerken van Amsterdam. Een vorm van hulp die in het wetsvoorstel zou worden verboden. Maar Susan is volledig afhankelijk van steun van kerken, bekenden of maatschappelijke organisaties. Haar huur (350 euro) wordt deels bekostigd door een Ghanese kerk uit de buurt, van het Wereldhuis krijgt ze supermarktvouchers voor 21 euro per week. Verder zijn er nog Ghanese vrienden en kennissen die haar regelmatig geld toestoppen, haar kleding wassen, en soms voor haar koken.
Susan huurt een slaapkamer in het appartement van een Ghanese, die ze via via kent. De slaapkamer staat tjokvol: een eenpersoonsbed, een houten tafel en een grote witte zuurstoftank zijn ingesloten door dozen en tassen. Er zijn strenge huisregels: Susan moet de flat schoonmaken, mag niet op de bank in de woonkamer zitten en bezoek is niet welkom.
Maar ze is allang blij met een bed. In Ghana groeide ze grotendeels zonder ouders op. Een man die haar „zielig vond” heeft haar vijfentwintig jaar geleden meegenomen naar Nederland. Samen hebben ze bij andere Ghanezen ingewoond. Soms was er geen matras, zegt Susan: „Dan sliep ik op een stoel aan de eettafel.”
Ruim tien jaar geleden heeft hij haar verlaten. „Hij zei: we zijn niet getrouwd, ik ben je niets verplicht.” Susan is sindsdien zeven keer verhuisd, ze heeft bijna altijd bij Ghanezen in Amsterdam Zuidoost ingewoond.
Aanvankelijk betaalde ze de huur uit eigen inkomsten: ze maakte jarenlang kantoren schoon in Amsterdam. Ze ‘leende’ de werkvergunning van iemand anders om zo ‘legaal’ te kunnen werken. Het loon werd op de bankrekening van degene met de werkvergunning gestort, die voor deze dienst een percentage rekende. De tussenpersoon hield een derde voor zichzelf. „Ik had weinig keus, anders kon ik niet eten.”
Aan het schoonmaakwerk kwam abrupt een einde toen ze tijdens een dienst struikelde over het snoer van de stofzuiger en van de trap viel. Sindsdien loopt ze met een rollator.
14.11 uur
Glimlachend loopt Patrick een Marokkaans eethuis binnen. „As-salamu alaykum, alles goed?” Hij gaat aan een tafeltje zitten en groet een man. „Hij heeft ook geen papieren”, fluistert Patrick.
Achter een bord dampende linzensoep vertelt Patrick dat hij naar Nederland is gekomen omdat er ruzie was in de familie. Zijn beide ouders zijn inmiddels overleden. Op een van zijn eerste dagen in Nederland bedacht hij een nieuwe naam voor zichzelf, voor als de politie hem aanhield – het werd Patrick Poitier. „P.P.”, zegt Patrick. „Dat klinkt goed en is makkelijk te onthouden.” Overal stelt hij zich voor als Patrick.
Inmiddels werkt hij niet meer, maar Patrick heeft verschillende ‘zwarte’ baantjes gehad. In een coffeeshop, in de garderobe van een dancing. Tegenwoordig komt hij rond van de 62 euro leefgeld die hij wekelijks krijgt van de gemeente. Zijn kamer krijgt hij van HVO-Querido, een opvangorganisatie voor dak- en thuislozen. Daar zit hij in de bewonerscommissie als onderdeel van zijn dagbesteding.
Patrick zit hij de bewonerscommissie van zijn opvanglocatie, als onderdeel van zijn dagbesteding.
Foto Mona van den Berg
Na de linzensoep neemt hij de metro naar de opvanglocatie. Er staat een bijeenkomst over de strafbaarstelling van illegaliteit op het programma. In de lichte ‘huiskamer’ staat een pooltafel en hangen lp’s aan de muur. Patrick neemt plaats op de bank met nog vijftien andere ongedocumenteerde mensen.
De projectleider ongedocumenteerden van de gemeente Amsterdam neemt het woord. „We zijn heel erg geschrokken van de aangenomen asielwet en de strafbaarstelling van ongedocumenteerden”, zegt de ambtenaar, die benadrukt dat Amsterdam het hier „niet mee eens is”. „Iedereen heeft recht op een bed, bad en brood”, zegt ze.
Een vraag uit de zaal. „Wat als je geen ID-kaart hebt en je wordt door de politie aangehouden?”
De ambtenaar: „We zijn nu met de politie hierover in gesprek. We willen afspreken dat ze ongedocumenteerden niet in detentie zetten.”
Patrick: „De politie mag je ook niet zomaar op straat stoppen en om je ID vragen.”
Sommige mensen hebben helemaal geen huis in hun thuisland. Die hebben niks
„Moeten alle ongedocumenteerden terug naar hun thuisland?”, vraagt een lange magere man.
Ambtenaar: „Dat wil de overheid, maar wij als gemeente Amsterdam niet. Sommige mensen hebben helemaal geen huis in hun thuisland. Die hebben niks.”
Een vrouw op de bank: „Ik wil graag met vriendinnen een dagje naar Duitsland of België. Kan dat?”
Patrick: „Ik heb gehoord dat mensen dan wel eens worden opgepakt.” Het is beter om niet te reizen, zegt de ambtenaar.
„En wat kun je zeggen tegen verklikkers? Mensen die zeggen: ik weet dat je illegaal bent, ik ga je verklikken”, vraagt een andere vrouw.
De ambtenaar: „Tegen die mensen kun je zeggen dat de wet nog niet is aangenomen door de Eerste Kamer. We werken aan een informatieve flyer hierover.”
Stilte in de zaal. Tijd voor de koffiepauze.
19.00 uur
Langzaam manoeuvreert Susan haar rollator langs laagbouwflats en rijtjeshuizen in Amsterdam Zuidoost. Na vijf minuten stopt ze en gaat op een muurtje zitten. Het zweet staat op haar voorhoofd.
Aan het eind van de middag moet Susan haar medicijnen nog ophalen, thuis mag ze geen post ontvangen van de huisbaas. Daarom laat ze haar medicijnen bezorgen bij een vriendin uit de buurt, een 74-jarige vrouw die een pakketpunt aan huis runt met haar dochter.
De deur gaat open. „Hey momma! How are you?” Een grote plastic tas met pakketjes verspert de doorgang in de gang. De dochter klapt de rollator in. Susan schuifelt de keuken in, waar een man een gezouten varkenspoot bereidt. Overal staan plastic tassen met daarin postpakketjes. In de vensterbank liggen pakjes uitgestald.
Susan huurt een slaapkamer in het appartement van een Ghanese, die ze via via kent.
Susan vlak voor haar vertrek uit Ghana, 24 jaar geleden.
Foto’s Mona van den Berg
De dochter geeft Susan een tas met medicijnen. „Hier kan ik drie maanden mee vooruit”, zegt Susan. Er staat een klant voor de deur. De dochter vist een pakketje uit de grote zak.
„Ze heeft weer een vriend”, zegt de vrouw tegen Susan en wijst naar haar dochter. „Hij woont in Ghana, maar in oktober komt hij hier naartoe. Hij is nog nooit in Amsterdam geweest”, zegt de dochter. „Ik voel me net een twintigjarige, zo verliefd.”
En Susan en de liefde? Ze kijkt naar de grond en dan omhoog, alsof ze haar eigen lichaam bekijkt. „Wie wil er een zieke vrouw?” De vriendin schudt haar hoofd, dan streng: „Dat moet je niet zeggen. Als God het wil.”
De bel gaat: twee kleuters huppelen de keuken binnen. „Come here, I missed you!” De kinderen knuffelen Susan. De 74-jarige vrouw geeft orders tijdens het koken: „Water, meer pepers, ui. Nu, mixen!”
„Ze is als een moeder voor me”, zegt Susan op weg terug naar huis. „Ze doet soms mijn was en brengt vaak eten.”
Iets voor middernacht zet Susan haar zuurstofmasker op en gaat ze naar bed. Ze heeft het masker nodig vanwege benauwdheidsklachten. Terug naar Ghana wil Susan niet, óók niet als illegaliteit in Nederland strafbaar wordt. Ze pakt een tas vol medicijnen uit haar slaapkamerkast. „Die kan ik hier krijgen.” Net als de grote witte zuurstoftank. „In Afrika zijn geen medicijnen voor mij, daar zou ik doodgaan.”
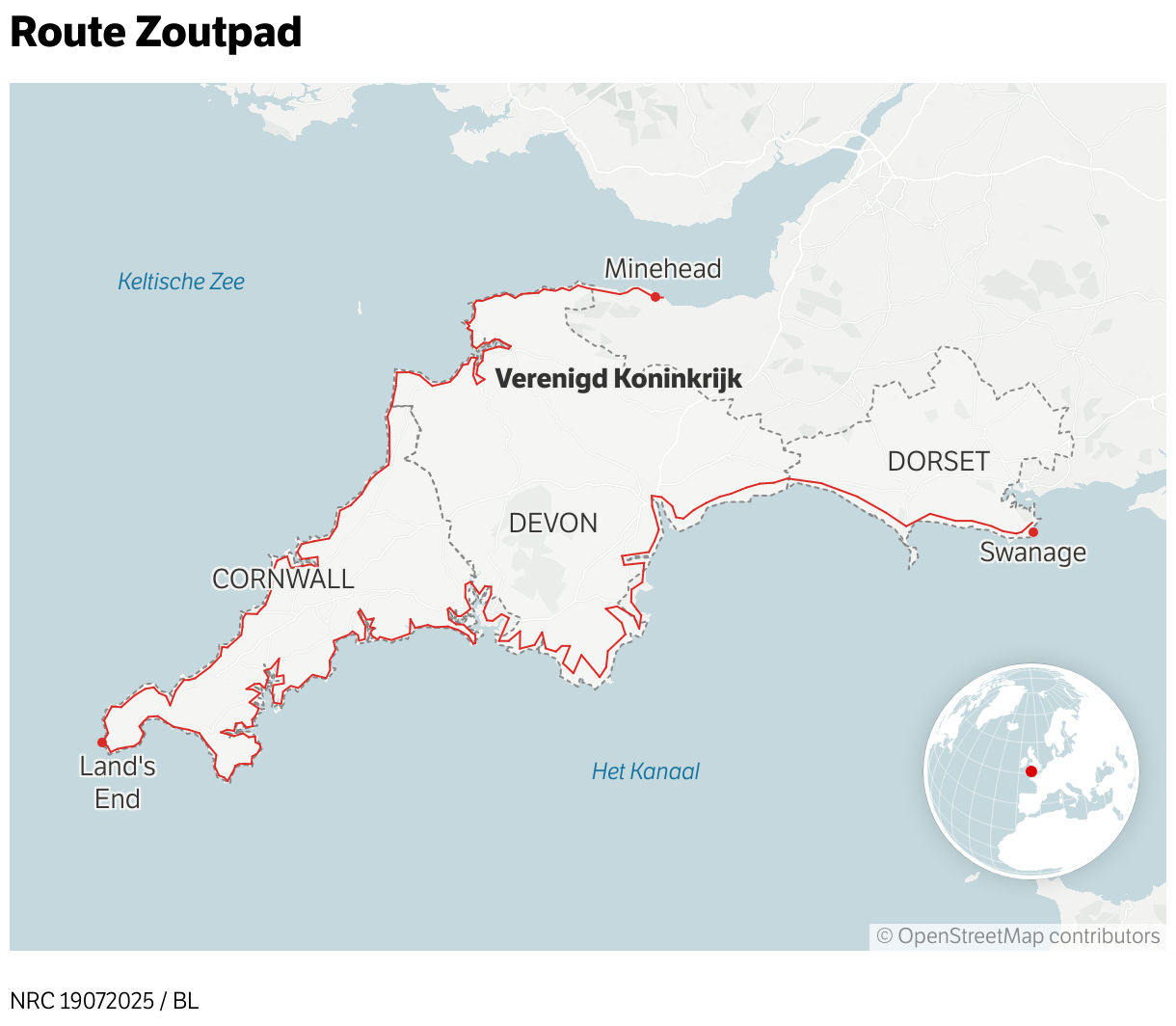
Op het pad halverwege Minehead en Porlock Weir zit een filosoof. Zijn rugzak tussen de varens, zijn blik op zee gericht, sjaaltje op het hoofd tegen de zon. Een jaar geleden zat Ian Mulholland (54) nog hele dagen achter de computer, terwijl hij de laatste hand legde aan zijn proefschrift over Wittgensteins Tractatus Logico-Philosophicus. Het was zijn dochter die vond dat hij eens met zijn neus uit de boeken moest. En dus verruilde hij zijn laptop voor een tent en een paar bergschoenen. De komende twee maanden loopt Mulholland het South West Coast Path, vandaag is zijn eerste dag. Nog 1.032,5 kilometer te gaan. Haast heeft hij niet. „De afgelopen uren ben ik voortdurend ingehaald – ik ben lang niet zo in vorm als andere wandelaars. En mijn rugzak is te zwaar door alle boeken die ik mee heb. Ach, het gaat om de reis, niet om het doel, zullen we maar zeggen.”
Onder filosofen is de Tractatus een klassieker. „Wittgenstein schreef over het verband tussen taal en werkelijkheid.” In die zin is het treffend dat Mulholland uitgerekend hier wandelt. Want als één langeafstandspad in de schijnwerpers staat vanwege de dunne lijn tussen feit en fictie dan is dat het South West Coast Path. Of, zoals het de laatste jaren bekend is komen te staan: het Zoutpad.
Terug naar het begin. Al weken staan de kranten vol over de Britse schrijfster Raynor Winn. In 2018 schreef ze een wereldwijde bestseller met The Salt Path, waarin ze vertelt hoe zij en haar man Moth dakloos raakten en in arren moede besloten ruim duizend kilometer langs de kust van Zuidwest-Engeland te wandelen, van Minehead via Land’s End naar Poole. Lezers leefden mee met alle ellende: te goeder trouw geld geleend aan een vriend die vervolgens bankroet ging, huis kwijt. Daarbovenop bleek Moth ook nog eens een zeldzame, dodelijke hersenziekte te hebben. Allemaal waargebeurd.
Of niet? Begin juli kwam zondagskrant The Observer met een groot stuk waaruit zou blijken dat Winn, onder haar echte naam Sally Walker, in een vorig leven als boekhouder ruim 60.000 Britse pond zou hebben verduisterd. Het verlies van het huis hing dáármee samen, aldus journalist Chloe Hadjimatheou. En had Moth wel echt corticobasale degeneratie? De levensverwachting bij die diagnose ligt normaal gesproken rond de acht jaar, terwijl Moth er al achttien jaar mee leeft.
Tot zover de controverse. Winn reageerde op haar eigen website met een tegenstuk, waarin ze de beschuldigingen zo goed mogelijk weerlegt. Maar de twijfel is gezaaid – het predikaat ‘waargebeurd’ zal voortaan met een korreltje zout worden genomen. Slechts één hoofdpersoon is verheven boven alle twijfel: het Zoutpad zelf. De natuur liegt nooit.
Op naar Minehead dus, in de voetsporen van de negen miljoen wandelaars die elk jaar het South West Coast Path deels of in z’n geheel lopen. Wat blijft er over van de trail magic als je de romantiek van het boek loslaat?
Foto Joel Redman
-35 kilometerTaunton
Reis nooit halsoverkop naar Minehead op een zondagavond. Dan strand je in Taunton, met nog 35 kilometer te gaan. Geen bus, geen trein, alleen peperdure taxi’s – lijnrecht tegen het Zoutpadgevoel in. Winn en Moth liftten óók als ze niet lopen konden. Duim omhoog dus, drie kwartier zo breed mogelijk glimlachen. Diepe dankbaarheid als locals Carl en Jo uiteindelijk stoppen. Nee, ze hebben het boek nooit gelezen, wel de film gezien. „Het was leuk om alle plekken te herkennen”, zegt Carl. „De bioscoop zat afgeladen vol.” Onder de indruk van de ophef zijn ze niet. „Het kustpad is het kustpad.”
Ook in de haven van Minehead reageren stamgasten van de Old Ship Aground gelaten op het nieuws. „Ook vóór het boek en de film kwamen er al volop toeristen”, zegt de barvrouw. „Die blijven echt niet zomaar weg.”
Op een rode brievenbus zit een gehaakte versie van Raynor Winn, met een eveneens gehaakt exemplaar van Het Zoutpad: in Minehead is ze nog niet van haar voetstuk gevallen.
Alleen een medewerkster van het Beach Hotel zegt „diep teleurgesteld” te zijn in Winn. „Bij het lezen dacht ik al: dit is bijna te indrukwekkend om waar te zijn. En dat was het dus ook.” Desondanks zet ze voor bezoekers die een exemplaar van het boek bij zich hebben zonder klagen een stempel van een eikel op het voorblad – het logo van het South West Coast Path.
Foto’s Joel Redman
0 kilometerMinehead
Rond tienen is het spitsuur bij het startpunt van het pad. Naast een gietijzeren monument – twee handen die een plattegrond vasthouden – maken Debbie en Neil Brooks een selfie. Vanuit hun woonplaats, nabij Southampton, lopen de vijftigers een weekendje langs het kustpad. Neil was aanvankelijk „behoorlijk ontdaan” toen hij de onthullingen over de schrijfster las. „Juist doordat het zo’n doorleefd verhaal is.” Hij frummelt aan zijn leren cowboyhoed. „Ze hadden beter kunnen zeggen dat het fictie was.” Debbie knikt. „Maar we maken er toch een mooie tocht van.”
Ook Ringo Vanovertveldt en Elfriede Dosfel uit het Belgische Ronse (twaalf etappes voor de boeg) zijn teleurgesteld in Winn. „Het was niet zo erg dat we er onze vakantie om gingen cancelen, maar het sprookjesachtige van het boek is weg.” De film hebben ze niet gezien. „Die is niet uitgebracht in België. Misschien dat we onderweg een cinema passeren.”
Ringo Vanovertveldt en Elfriede Dosfel: „Het sprookjesachtige van het boek is weg.”
Foto Joel Redman
2,9 kilometerNorth Hill
Was het Simon Carmiggelt die ooit zei: „Een schrijver liegt de waarheid”? Wie schrijft maakt keuzes, laat dingen weg – zelfs in een waargebeurd verhaal. Beschrijf ik de gele bloemen langs de Culver Cliff Woodland Walk, de tentjes van wandelaars of daklozen die her en der in het hoge gras verscholen staan? Of begin ik direct over de steile klim de North Hill op, door een sprookjesachtig varenbos? En welke rol speelt fotograaf Joel? Noteer ik eerlijk hoe ik al buiten adem ben terwijl hij met z’n zware camera om z’n nek nergens last van heeft?
Tussen schrijvers en lezers bestaan ongeschreven afspraken die per genre verschillen – zelfs binnen de non-fictie. Een feitelijk nieuwsbericht kent andere wetten dan een ik-verhaal. Verzinnen telt buiten de fictie als een zwaarder vergrijp dan weglaten, tenzij het cruciale informatie betreft. En dat laatste is juist bij Het Zoutpad een discussiepunt: hoe belangrijk was de verduistering van 60.000 pond voor het verhaal?
Het gaat om authenticiteit, zegt Joel terwijl hij een vlinder fotografeert. „Mensen waarderen openheid en transparantie. Als blijkt dat iemand zo’n groot geheim verzwijgt, dan straalt dat af op de rest. Neem die ziekte van Moth – die kan best echt zijn, ook al omschrijven diverse artsen het als ‘onwaarschijnlijk’ omdat hij nog leeft. Maar nu het verhaal niet authentiek meer voelt, trekken lezers álles in twijfel.”
Intussen gaat Max Wilgenhof (26) uit Alkmaar ons in hoog tempo voorbij. Hij hoorde pas kort voor vertrek van familie over de ophef. „Ik heb het boek gelezen en ik had het mooier gevonden als het waargebeurd was, maar uiteindelijk ben ik hier om te wandelen.” Hij hoopt in 28 dagen het gehele pad af te leggen, zo’n 35 kilometer per dag. „Het gaat me om de prestatie, om mezelf discipline aan te leren.” Slapen doet hij onder een tarp, een lichtgewicht tentje zonder binnentent. „Zonder eten weegt m’n rugzak acht kilo, ik heb echt alleen het minimale mee.”
Max Wilgenhof: „Ik had het mooier gevonden als het waargebeurd was”
Anna Ender en Anouk van Heel.
Foto’s Joel Redman
5,1 kilometerBurgundy Chapel
De Nederlandse vriendinnen Anna Ender (25) en Anouk van Heel (24) maken zich minder zorgen over het gewicht van hun backpack. Ze hebben een pot pindakaas mee, een knijptube jam en bij de Flapjackery hebben ze vanochtend snacks ingeslagen. Boven aan de heuvel is het tijd voor een picknick. De bomen hebben plaatsgemaakt voor grasland en brem, in de diepte ruist de zee. Zeven dagen gaan ze wandelen, 4.500 hoogtemeters in totaal – „een halve Everest”. Anouk kent het boek en de film alleen van naam. Anna herinnert zich vooral de scène waarin de zee de tent in stroomt. „Gelukkig kamperen we niet.”
Op een bankje drinken twee Engelse mannen bier. „Welkom in onze open air pub.” Al dat gepraat over Het Zoutpad vinden ze overdreven. „Maak je liever zorgen om adders op het pad.”
Tentjes bij de Culver Cliff Woodland Walk, nabij North Hill.
Foto Joel Redman
6 kilometerGrexy Combe
Dalen. Stijgen. Dalen. Stijgen. Het geel van de brem vermengt zich met het paars van de heide. In de verte lopen groepjes wandelaars. Op het Zoutpad ben je nooit alleen.
Toch is het een illusie om te denken dat alleen dít langeafstandwandelpad de afgelopen jaren populairder is geworden. Op de wereldberoemde pelgrimsroute naar Santiago de Compostella verdubbelden de aantallen wandelaars tussen 2014 en 2024. Santiago staat voor Sint Jacob, een van de apostelen van Jezus. In de kathedraal van de stad zouden zijn overblijfselen begraven liggen. Hoeveel wandelaars zouden teleurgesteld zijn als dát verhaal verzonnen blijkt?
Opeens schiet Fargo me te binnen, de film van de Coen Brothers over een man die de ontvoering van zijn eigen vrouw in gang zet. „This is a true story”, staat er in hoofdletters aan het begin van de film. Niets van waar, zei Joel Coen later. Het leek geen fan te deren.
Ook Steve Tornhill en Tracey Wade, die hier al jaren komen, vinden dat artistieke vrijheid is toegestaan. Tracey neuriet het nummer Shame, van oud-Take That-leden Robbie Williams en Gary Barlow: „Well there’s three versions of this story / Mine and yours / And then the truth.”
Steve Tornhill en Tracey Wade: „Well there’s three versions of this story…”
Ian Mulholland: „Als je het een filosoof vraagt, bestaat er helemáál geen waarheid.”
Foto’s Joel Redman
7,5 kilometerhalverwege Minehead en Porlock Weir
„Als je het een filosoof vraagt, bestaat er helemáál geen waarheid”, zegt Ian Mulholland. Naar Raynor Winn toe is hij mild. „Mensen doen dat wel vaker: eerst iemand op een voetstuk zetten om diegene dan…” – hij gebaart over de rand van het klif – „…er keihard weer vanaf te duwen.”
10 kilometerHurlstone Point
„Waarschuwing! Neem bij harde wind de alternatieve route”, staat op het bordje. Koppig kiezen we tóch de steile afdaling naar het kiezelstrand. Een hurlstone is vrij vertaald een werpsteen. Wie zonder zonde is…
Ook fotografen liegen de waarheid, besef ik als Joel zoekt naar het mooiste standpunt. Zelfs als er geen Photoshop of filter aan te pas komt, is er altijd nog de kadrering – een lelijk hekje of een dode boom die op de foto nét buiten beeld valt.
Langs de muur van Hadrianus, op de grens van Engeland en Schotland, hakten twee mannen in 2023 de beroemde Sycamore Gap Tree om. Een 150 jaar oude esdoorn, alom geliefd vanwege z’n fotogenieke uiterlijk. Deze week zijn de daders beiden veroordeeld tot ruim vier jaar gevangenisstraf. Volgens de rechter is Engeland een „symbool van ongerepte schoonheid” armer. Kom niet aan het emotionele erfgoed van de Britten, of dat nu een boom of een boek betreft.
11,5 kilometerBossington
De idyllische theetuin is dicht. In Het Zoutpad beschrijft Winn hoe ze hier tijdens een cream tea – thee met scones – met de nek worden aangekeken zodra ze vertellen dat ze dakloos zijn. Eerlijkheid loont niet altijd.
We hebben dorst en beëindigen de tocht voortijdig in de supermarkt, met een sinaasappel-Calippo. Dat is het nadeel van waargebeurde verhalen: ze hebben zelden een heroïsch einde.
Maren (9) pakt haar tablet erbij aan de keukentafel in Delft en opent YouTube. De nieuwste video van MrBeast staat meteen bovenaan in haar aanbevelingen. Echt fan zou ze zich niet noemen, maar hij is er gewoon altijd als ze naar YouTube gaat. In de video die nu afspeelt, gaat MrBeast met zijn vriendin op romantische dates, een met een prijskaartje van 1 dollar en een van een half miljoen. „Ze kregen heel Disney voor zichzelf”, zegt Maren. „Dat was voor het eerst in de hele Disney-geschiedenis.” Voor iemand als MrBeast, de 27-jarige Amerikaan James ‘Jimmy’ Donaldson, is zo’n groots uitje best standaard. Hij doet immers altijd „allemaal coole dingen”.
Twintig jaar na de oprichting is YouTube nog altijd het grootste videoplatform ter wereld, en voor veel kinderen het startpunt van hun online leven. Van de twintig grootste YouTube-kanalen richten elf zich op kinderen, van peuters tot pubers. YouTube is voor deze generatie kinderen net zo vanzelfsprekend als televisie dat vroeger was. Het platform staat klaar met een eindeloze stroom video’s, afgestemd op hun aandacht en interesse.
Dat is goed te zien bij MrBeast, de grootste youtuber ter wereld met 409 miljoen abonnees. Zijn video’s zijn ontworpen om de aandacht van jonge kijkers al vanaf de eerste seconde te grijpen. Niet alleen de inhoud is op hen toegesneden, maar ook de toon. MrBeast schreeuwt bijna continu, het scherm knippert van de snelle shots en lichtflitsen. MrBeast heeft zich het algoritme van YouTube volledig eigen gemaakt; zijn populairste video’s zijn hyperbolische spektakels waarin het draait om grote geldbedragen, competitie en overleven – vaak dat allemaal tegelijk.
Zo herinnert Maren zich een video waarin hij een levensechte versie bouwt van de chocoladefabriek uit Sjakie en de chocoladefabriek. Alles is er: glijbanen van chocolade, fonteinen, snoepkastelen, een lopende band vol lekkers. „En dan zijn er een paar mensen die een ticket hebben gevonden, net zoals in de echte film. En dan gaan ze daarnaartoe en moeten ze allemaal challenges doorstaan. En wie overblijft, wint”, legt ze uit. Groots, absurd en recht uit de fantasiewereld van een kind.
Zijn producties komen voort uit een even kinderlijke nieuwsgierigheid. Hoe zou het zijn om levend begraven te worden? Zou je in een badkuip vol slangen zitten als ik je moeder 10.000 dollar zou geven? Zit je liever gevangen in de koudste of in de heetste kamer ter wereld? Zijn best bekeken video, $456,000 Squid Game In Real Life! (820 miljoen weergaven), bootst de Netflix-serie Squid Game na met echte mensen en echte geldprijzen. Maar dan zonder fatale gevolgen voor de ‘uitgeschakelde’ spelers.
<figure aria-labelledby="figcaption-0" class="figure" data-description="Maren (9) pakt haar tablet erbij aan de keukentafel in Delft en opent YouTube. De nieuwste video van MrBeast staat meteen bovenaan in haar aanbevelingen.” data-figure-id=”0″ data-variant=”grid”><img alt data-description="Maren (9) pakt haar tablet erbij aan de keukentafel in Delft en opent YouTube. De nieuwste video van MrBeast staat meteen bovenaan in haar aanbevelingen.” data-open-in-lightbox=”true” data-src=”http://nltoday.news/wp-content/uploads/2025/07/elke-seconde-telt-hoe-populaire-youtubers-als-mrbeast-de-aandacht-van-kinderen-vangen-en-vasthouden.jpg” data-src-medium=”https://s3.eu-west-1.amazonaws.com/static.nrc.nl/wp-content/uploads/2025/07/18141604/data135059871-5724e2.jpg” decoding=”async” src=”http://nltoday.news/wp-content/uploads/2025/07/elke-seconde-telt-hoe-populaire-youtubers-als-mrbeast-de-aandacht-van-kinderen-vangen-en-vasthouden-10.jpg” srcset=”http://nltoday.news/wp-content/uploads/2025/07/elke-seconde-telt-hoe-populaire-youtubers-als-mrbeast-de-aandacht-van-kinderen-vangen-en-vasthouden-8.jpg 160w, http://nltoday.news/wp-content/uploads/2025/07/elke-seconde-telt-hoe-populaire-youtubers-als-mrbeast-de-aandacht-van-kinderen-vangen-en-vasthouden-9.jpg 320w, http://nltoday.news/wp-content/uploads/2025/07/elke-seconde-telt-hoe-populaire-youtubers-als-mrbeast-de-aandacht-van-kinderen-vangen-en-vasthouden-10.jpg 640w, http://nltoday.news/wp-content/uploads/2025/07/elke-seconde-telt-hoe-populaire-youtubers-als-mrbeast-de-aandacht-van-kinderen-vangen-en-vasthouden-11.jpg 1280w, https://images.nrc.nl/uDqm8NybMd46jGZT_frIMEO61fY=/1920x/filters:no_upscale()/s3/static.nrc.nl/wp-content/uploads/2025/07/18141604/data135059871-5724e2.jpg 1920w”>
Maren (9) pakt haar tablet erbij aan de keukentafel in Delft en opent YouTube. De nieuwste video van MrBeast staat meteen bovenaan in haar aanbevelingen.
Foto’s Saskia van den Boom
Haar eerste iPad
Wanneer Maren precies begon met YouTube kijken weet ze niet meer. Volgens haar moeder was ze drie jaar oud toen ze haar eerste iPad kreeg. Haar broer had er ook een, zodat ze er geen ruzie over zouden krijgen. Ze kijkt soms ’s ochtends voor school. „Meestal best kort”, zegt ze, „maar ’s avonds best wel lang. Ik denk drie kwartier.” Wat ze kijkt wisselt – wat voorbijkomt, wat opvalt. Een tijdslimiet staat niet ingesteld, maar soms grijpen haar ouders in: „Dan zeggen ze: nu even stoppen.”
„Ik heb een tablet sinds ik twee was, denk ik”, zegt Sura (10), thuis in Den Haag. „Dus bijna mijn hele leven.” Op haar telefoon is een tijdslimiet ingesteld. „Als de tijd om is, komt er zo’n slotfiguurtje in beeld en dan moet ik hem uitzetten. Dat heeft papa zo gedaan, zodat ik niet te veel op mijn telefoon zit.” Op gewone dagen mag ze een half uur schermtijd, in het weekend twee uur. „Ik kijk meestal in het weekend naar YouTube.”
Voor Jan (9) uit Amsterdam is YouTube inmiddels een dagelijkse routine. Eerst mocht hij voor hij naar school ging altijd een filmpje van acht minuten kijken van zijn vader. Maar het uitkiezen van een filmpje duurde zo lang, dat hij nog maar weinig tijd overhield. Nu kijkt hij na school drie kwartier, maar dan wel met een timer die hij zelf instelt. Dat helpt, zegt hij: „Je moet ook een beetje leren wat de waarde is van een uur YouTube.”
Ik heb een tablet sinds ik twee was, denk ik
Uit recent onderzoek van Netwerk Mediawijsheid blijkt dat kinderen tot en met zes jaar gemiddeld 86 minuten per dag aan digitale media besteden, vaak via tv of tablet. Een derde gebruikt al een smartphone. Volgens de Monitor Mediagebruik 7-12 jaar keken kinderen in 2021 (recentere cijfers zijn er niet) gemiddeld 44 minuten per dag naar YouTube, waarschijnlijk meer tijdens de coronalockdown.
37 procent van de ouders noemde YouTube het favoriete platform van hun kind, vooral vanwege gamevideo’s. Maren, Sura en Jan kunnen dat beamen. De meiden kijken het allerliefst naar Lana’s Life, het kanaal van YouTuber Lana Rae die video’s maakt over het spel Dress to Impress in de online gamewereld Roblox, waarin spelers virtuele outfits samenstellen rond een thema, bijvoorbeeld ‘zomerfeest’ of ‘beroemde filmster’, en elkaars looks beoordelen. „Ze doet challenges, zoals wie het snelst een outfit kan maken of wie het beste een stijl kan namaken, of ze laat kijkers op haar outfit stemmen”, zegt Sura. „Of ze maakt bekende avatars, zoals een emo-meisje, een rijke influencer of een populair Roblox-personage.”
Jan zit in een heel andere gamehoek van YouTube. Zijn favoriete maker is Fireb0rn, een relatief onbekende youtuber die lange, analytische video’s maakt over strategieën en vijanden in het actie-avontuurspel Hollow Knight. Jan kijkt het liefst naar mensen die het spel voor het eerst spelen. „Dat vind ik grappig, omdat je ziet hoe ze alles nog moeten ontdekken.”
Filmpjes worden zelden uitgekeken, er is immers aanbod zat. „Ik kijk filmpjes niet helemaal”, zegt Sura. „Alleen de stukjes die ik leuk vind.” Jan speelt video’s op dubbele snelheid af als hij het saai vindt. Maren: „Als het niet zo leuk is, klik ik weer weg.” Na een paar minuten vaak al.
Algoritmes hebben grote invloed. „Als ik één filmpje van Lana kijk, komen er daarna nog tien”, zegt Maren. Dat vindt ze handig: „Dan hoef ik niet te zoeken.” Sura: „Als je Dress to Impress kijkt, zie je daar meer van. Als je veel eetvideo’s kijkt, zie je ook veel eetdingen.” Kinderen worden geleid door het aanbod – door shorts (verticale filmpjes van maximaal 180 seconden), aanbevelingen, thumbnails (het plaatje waarmee de video wordt aangekondigd). Ze klikken op wat opvalt, of kijken naar iets dat automatisch begint te spelen. Soms weten ze achteraf niet eens meer wat ze hebben gezien.
Jan (9) mocht voor hij naar school ging altijd een filmpje van acht minuten kijken van zijn vader. Maar het uitkiezen duurde zo lang, dat hij nog maar weinig tijd overhield. Nu kijkt hij na school drie kwartier.
Foto Saskia van den Boom
How to Succeed
MrBeast duikt vanzelf op het scherm van Maren op. Ze wijst naar een thumbnail van een filmpje. „Would you risk drowning for… een heel groot bedrag”, leest ze voor. 500.000 dollar. „Dan denk ik: ik wil liever gewoon leven zonder geld dan verdrinken met zoveel geld.” Ze heeft gemengde gevoelens over zijn filmpjes. „Hij doet een beetje gek en schreeuwt veel.” Toch kwam ze halverwege.
Dat de video’s van MrBeast zo populair zijn, is geen toeval. „Ik heb vijf jaar van mijn leven opgesloten gezeten in een kamer om virale video’s te bestuderen”, schrijft hijzelf in een document van 36 pagina’s dat vorig jaar uitlekte, getiteld ‘How to Succeed at MrBeast Production’. „Twintig- tot dertigduizend uur later weet ik aardig wat een YouTube-video succesvol maakt.” Hij beschrijft hoe zijn team van honderden medewerkers, gevestigd in een gigantisch hoofdkantoor van bijna zesduizend vierkante meter in North Carolina, video’s maakt die kijkers tot het einde vasthouden.
Daardoor zijn de video’s van MrBeast niet zomaar entertainment, maar een afspiegeling van de interne logica van YouTube. MrBeast dook diep in de data van het platform, experimenteerde met thumbnails, titels, montages, spanningsbogen en timing, en keek wat werkte en wat niet. Alles draaide om één doel: begrijpen hoe je mensen vasthoudt en het algoritme tevreden stelt. Iedere seconde telt, vooral in de eerste minuut – het moment waarop de meeste kijkers afhaken. Daarom worden zijn video’s niet rustig opgebouwd, maar word je in de openingsscènes overdonderd met beelden en geluid – een shot dopamine.
YouTube zelf ziet MrBeast als voorbeeld van wat er technisch en strategisch mogelijk is op het platform. De schaal waarop MrBeast opereert, zet druk op het onlineplatform om te blijven innoveren. „Hij daagt ons voortdurend uit”, zegt Sam Vergauwen, YouTubes country manager in de Benelux. „Hij wil alles: meerdere audiotracks, zodat kijkers bijvoorbeeld hun eigen taal kunnen selecteren; advertenties in livestreams; en automatische dubbing [nasynchronisatie in andere talen].”
Overbelast
Wat doen die hyperactieve, eindeloos aanbevolen video’s met jonge kijkers? Garth Graham, directeur van YouTube Health – het onderdeel van het platform dat betrouwbare medische informatie toegankelijker moet maken – wil zich niet uitspreken over het effect van MrBeast. „Ik heb geen studies gezien die aantonen dat één specifieke maker verslavend werkt”, zegt hij.
Neuropsycholoog Marion van den Heuvel benadrukt dat het precieze effect lastig te bepalen is, vooral vanwege ethische bezwaren. „Waterdicht bewijs zullen we waarschijnlijk nooit krijgen”, zegt ze. „Je kunt kinderen moeilijk voor een wetenschappelijk onderzoek een periode lang de halve dag voor een tablet zetten en kijken wat er gebeurt.”
Van den Heuvel is universitair hoofddocent aan Tilburg University en onderzoekt hoe ervaringen in de vroege kindertijd de ontwikkeling van het kinderbrein beïnvloeden. Filmpjes kunnen leerzaam zijn, zegt ze, „maar als je zó veel input krijgt, kan je het niet allemaal verwerken.” Het brein raakt overbelast door de constante stroom aan beelden, en moet hard werken om bij te blijven. Bij video’s die bedoeld zijn voor baby’s ziet ze dat flitsende beelden worden gecombineerd met woorden als apple, blue, tree en green om het leren van Engels te stimuleren. „Maar het brein van die baby is eerst bezig met: wat ís dit allemaal?”
Graham van YouTube Health wijst op platformbrede maatregelen die het bedrijf heeft genomen om jonge kijkers te beschermen: pauze- en bedtijdmeldingen die automatisch verschijnen na ongeveer een uur kijken voor gebruikers onder de achttien jaar. Die meldingen nemen het hele scherm over, maar zijn makkelijk weg te klikken. Daarnaast zijn er ‘vangrails’ ingevoerd om te voorkomen dat jongeren te veel content consumeren over mogelijk schadelijke thema’s, zoals uiterlijk en lichaamsgewicht, geld of agressie. Het algoritme beperkt dan bijvoorbeeld aanbevelingen van video’s over geïdealiseerde lichaamstypes, maniertjes om snel rijk te worden of filmpjes waarin mensen in het openbaar worden vernederd.
Sura kijkt graag naar Lana’s Life: „Ze doet challenges, zoals wie het snelst een outfit kan maken of ze laat kijkers op haar outfit stemmen”.
Foto’s Saskia van den Boom
Brainrot
Als Sura op YouTube zit, is het „niet echt” makkelijk meer om haar iPhone weg te leggen. „Als je hem eenmaal pakt, let je niet meer op de tijd. Dan zit ik er ineens een uur op, terwijl het lijkt alsof het maar tien minuten is.” Vooral shorts slurpen haar aandacht op. „Elke keer iets anders.”
Haar moeder ziet hoe dat werkt: „Steeds ander geluid, ik vind het zonde van haar tijd. Hoe noem je dat ook alweer, als je brein overprikkeld raakt? Brainrot?”
„Jij moet de macht hebben over de tablet, niet andersom”, zegt neuropsycholoog Van den Heuvel. „En daar moet je kinderen in opvoeden. Want het algoritme wil maar één ding: dat jij zo lang mogelijk blijft kijken.”
Het herkennen van prikkels en de invloed daarvan op je hersenen is cruciaal, zegt ze. „Juist in deze tijd, waarin er zó veel prikkels zijn, moet je kinderen leren omgaan met: ben ik overprikkeld? Is dit ontspannen of eigenlijk niet? Vind ik het echt leuk wat ik aan het kijken ben?”